Introduction
Gathering Cyber Threat Intelligence data is fairly easy, especially OSINT. There are so many feeds out there that will stream IOCs to your aggregation platform that you will most likely be overwhelmed with a mix of high and low fidelity intelligence.
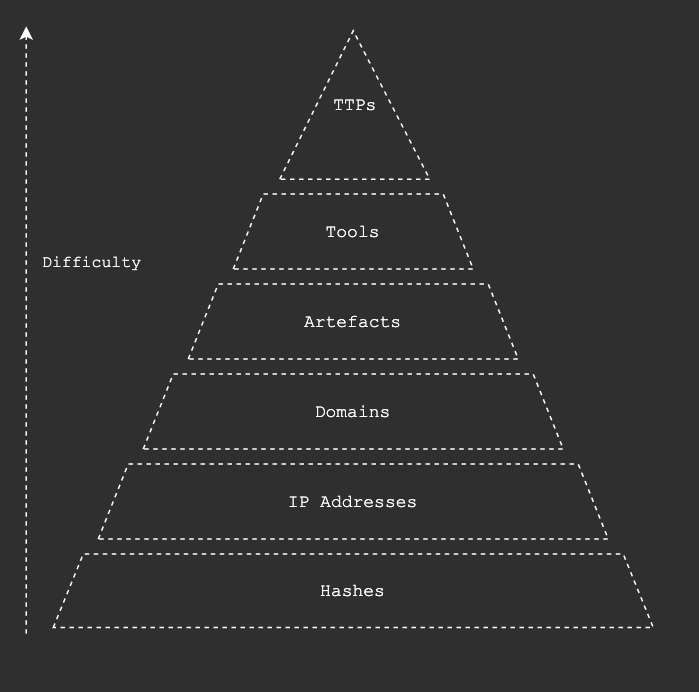
When we think about the Pyramid of Pain by David Bainco ingesting huge amounts of malicious hash values is not a big deal, these malicious hashes won’t change and so collecting them and pushing them to detection technologies isn’t particularly taxing. However this comes with a caveat, as malware has become more polymorphic in nature, we can’t rely on collecting out of date hashes for malware samples.
Similarly, IP addresses get re-assigned and as more cloud services and virtual hosts are used mean that false positives are almost guaranteed.
As we move up the pyramid the indicators become harder to collect, correlate and apply to security tooling.
We can therefor predict that the volume of data collected for each rung can be represented by the rung’s size, potentially millions of hashes and a few hundred TTPs for example.
Introduction to the CODE Model
The CODE model is a framework that can be used to help Security Operations make sense of the wealth of Threat Intelligence data available to them.
Collect
This is where most of the front-loaded effort comes in, selecting good quality sources to suit your environment is the difference between high quality alerting and enrichment and one to two hundred alerts with 80% false positive rate.
- OSINT: There is a wealth of open source intelligence on the internet, RSS feeds on infosec blogs, websites and vulnerability reports are all great places to start when beginning a threat intelligence function. Twitter has a host of fantastic up to the minute pieces of CTI data provided to the community by twitter accounts such as @Cryptolaemus1 and @MalwareHunterTeam. When new CVEs drop you’ll find it on twitter, when new exploit code released, it’ll be on Twitter in minutes.
- Partners: Orgs such as ISACAs share threat intelligence (frustratingly this is done usually over email)
- Endpoints and SEIM: Your own systems, true positives should be tracked and stored just like any other piece of threat intelligence data.
- HUMINT: Talking to colleagues, Signal / Telegram groups etc …
- Research: Doing research on malware that has been detected on your environment. I really like to browse Any.Run, Malware Bazar and VirusTotal as well.
- 3rd Party: CTI providers such as Recorded Future etc …
Organise
Create a knowledge base to store findings, IOCs and aggregate feeds. There are many great OpenSource solutions for this such as MISP and OpenCTI.
This is where most SOC functions fall down, simply squirting CTI feeds into a SEIM is accomplishing something but without a proper method the SOC could quickly be overwhelmed with false positives and little contextual knowledge of what is firing alerts. Taking up precious investigation time.
I will write some posts going into more detail on this in the future.
Distill
This phase is where all of the data collected is distilled down to something more manageable, something that can answer the ‘why should we care about this’ type of questions and building structures with the data, such as mapping your collected information to TTPs and Adversaries, which can be used for threat hunting.
The main objectives here are to:
- Remove / reduce false positives: checking IPs / URLs against other TI sources, information about shared hosting providers, checking for IP ranges for AWS and Azure are also a good bet to check if an IOC will fire with a lot of false positives. It’s also worth automatically checking for clangers such as 127.0.0.1 and other common false positive generators. This will save some embarressment down the line too.
- Perform analytics on the data being aggregated: can we draw conclusions about incoming spamwaves? How about changes to malware that has happened overnight, does that mean detections need to change? etc etc etc …
- Recycle the information coming from detection technologies and the SOC team to understand what threats are actively impacting the environment, this information can then be used to shore up ingress points.
- All of the above should be performed to reduce risk in the environment. Having knowledge of the threat is simply not enough, we must be able to publish actionable intelligence to inform stakeholders of what measures need to be taken to reduce risk. Which brings me nicely onto my next point…
Express
The final part of a well integrated threat intelligence operation is communicating your findings and providing concise and actionable information where it is needed.
- Disseminate: Inform different teams / levels of business differently, the SOC team will need more technical information about a threat such as TTPs, IOCs and common escalation paths so they know where to look to remediate a threat. Exec level will be more focused on risk and why they should care about a new module that has been added to Emotet.
- Inform Detection: use the understanding you have gained to craft detections for malware, common escalation paths, ways of detecting that new vulnerability that you know can’t/won’t be patched anytime soon. SEIM and EDR tooling typically allow streaming of IOC data directly into the platform, there’s little point sitting on top of a mounting of IOCs like a dragon would sit on a pile of gold. If you have confidence in the quality of the IOCs you are collecting, stream them to these platforms, you may be surprised how many hits you get for things you have previously missed.
Conclusion
I hope this brief introduction into the high level outline of how I think about operationalising cyber threat intelligence proved useful. I will continue to write posts about these concepts in greater detail with some more tips and great open source tooling that can be used at any level of maturity.